As we said in section 1.3 Rational Function Optimization is a second order method[130,131,245]. It is basically a Newton-Raphson procedure, a Hessian eigenmode following algorithm that avoids the inversion of the Hessian matrix and provides an implicit determination of step length.
Although we already described the mathematics of RFO method in the introduction section 1.3.4.2, now we will give a handful explanation of the method that will stand out the advantages and the difficulties of its practical usage.
RFO is an iterative process that can be outlined as follows:
![\includegraphics[width=0.6\textwidth]{Figures/scheme.eps}](img481.png)
We first build the Augmented Hessian(AH), which is the Hessian matrix (![]() ) with an additional row and an additional
column that contains the gradient.
) with an additional row and an additional
column that contains the gradient.
At every iteration ![]() the (N+1) eigenvalue system must be solved
the (N+1) eigenvalue system must be solved
The quadratic variation energy
![]() is evaluated as
is evaluated as
The ![]() eigenvalue system (equation 3.2) may be solved completely
if we want to check at every step the correct concavity of the PES.
If this is not the case, a partial diagonalization that only gives the two lowest
eigenpairs will be enough to calculate the displacement (equation 3.3) and proceed with the search4.2.
eigenvalue system (equation 3.2) may be solved completely
if we want to check at every step the correct concavity of the PES.
If this is not the case, a partial diagonalization that only gives the two lowest
eigenpairs will be enough to calculate the displacement (equation 3.3) and proceed with the search4.2.
Updating formula for the Hessian matrix:
When we are trying to locate a minimum with RFO, the Hessian matrix is updated using a modified form of the BFGS formula[12].
The most general rank-two update Hessian matrix formula is
The proposed modified form of the BFGS expression only differs with respect to the normal BFGS in the calculation
of the two scalars ![]() and
and ![]() . In this modified form these two scalars are evaluated as
. In this modified form these two scalars are evaluated as
For location of first-order saddle points the Powell formula is used, where in this case the matrix ![]() contained in equation 3.5 is equal to unit matrix
contained in equation 3.5 is equal to unit matrix ![]() .
.
Acceleration of optimization process: DIIS
We implemented the Direct Inversion of Iterative Space to the gradient vector (GDIIS) as a process to accelerate the convergence
in the vicinity of the stationary point.
As described in section 1.3.4.3
a combination of the previous gradient vectors is used so as to minimize the length of the current gradient vector.
The GDIIS procedure has only been used in a development stage of the source code. We saw that the quality of a good initial Hessian could improve in a more efficient way the convergence process. So it is not used in the test systems nor in the forthcoming sections of application to enzymatic systems.
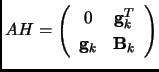
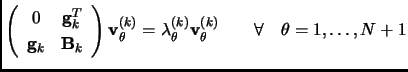
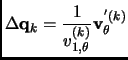
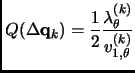
![$\displaystyle {\bf B}_{k+1}={\bf B}_0+\sum_{i=0}^k[{\bf j}_i{\bf u}_i^T +{\bf u...
..._i^T -({\bf j}_i^T \Delta {\bf q}_i){\bf u}_i {\bf u}_i^T ] \qquad k=0,1,\ldots$](img286.png)
![$\displaystyle a_i=\frac{[{\bf A}^T_i {\bf D}_i]^2}{({\bf A}^T_i{\bf A}_i)({\bf D}^T_i){\bf D}_i}$](img486.png)